
GGUF 양자화 포맷별 성능 벤치마크
서두
이 글은 GitHub Gist에 작성한 GGUF Quantization TPS Comparison(영어)을 한국어로 블로그에 옮겨적어두는 글이다. 아무래도 블로그가 검색 접근성이 좋을테니…
이 벤치마크는 통제된 상황에서 전문적으로 수행된 벤치마크가 아닌, 그냥 대충 돌린 벤치마크이므로, 수치를 직접적으로 참고하지는 마시고, 그냥 포맷별 성능 편차가 어느 정도인지 참고하는 정도로만 써주시면 좋겠다.
- 모델: Gemma 3 4B, bartowski님의 양자화 모델 (링크)
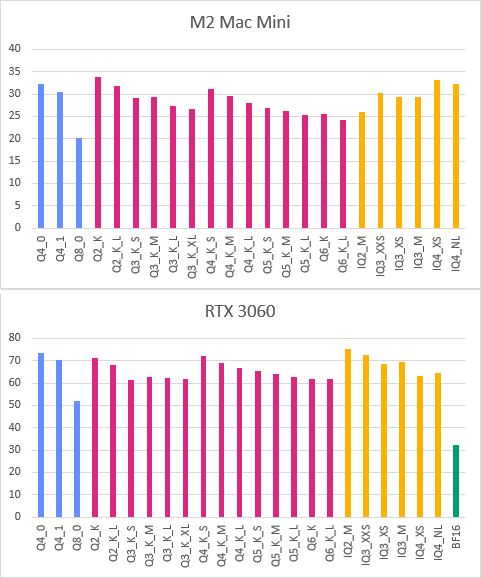
M2 Mac Mini, 16GB RAM, llama.cpp b4980 (brew)
- 명령:
llama-cli -p "Tell me a long story." -m [model]
| 양자화 포맷 | PP (t/s) | TG (t/s) |
|---|---|---|
| Q4_0 | 143.23 | 32.27 |
| Q4_1 | 142.08 | 30.44 |
| Q8_0 | 145.55 | 20.20 |
| Q2_K | 131.36 | 33.80 |
| Q2_K_L | 120.12 | 31.85 |
| Q3_K_S | 124.46 | 29.04 |
| Q3_K_M | 122.61 | 29.27 |
| Q3_K_L | 120.49 | 27.23 |
| Q3_K_XL | 124.63 | 26.64 |
| Q4_K_S | 128.79 | 31.06 |
| Q4_K_M | 123.30 | 29.60 |
| Q4_K_L | 122.80 | 27.93 |
| Q5_K_S | 118.89 | 26.91 |
| Q5_K_M | 115.35 | 26.13 |
| Q5_K_L | 116.06 | 25.30 |
| Q6_K | 130.00 | 25.57 |
| Q6_K_L | 121.78 | 24.25 |
| IQ2_M | 132.85 | 26.00 |
| IQ3_XXS | 130.72 | 30.31 |
| IQ3_XS | 121.95 | 29.41 |
| IQ3_M | 118.38 | 29.40 |
| IQ4_XS | 133.84 | 33.13 |
| IQ4_NL | 133.18 | 32.33 |
Windows 10, RTX 3060, 12GB VRAM, llama.cpp b4980-cu12.4 (GitHub 릴리즈)
- 명령:
llama-cli -p "Tell me a long story." -ngl 100 -m [model]
| 양자화 포맷 | PP (t/s) | TG (t/s) |
|---|---|---|
| Q4_0 | 442.16 | 73.40 |
| Q4_1 | 578.66 | 70.37 |
| Q8_0 | 512.17 | 52.08 |
| Q2_K | 396.75 | 71.45 |
| Q2_K_L | 458.73 | 67.99 |
| Q3_K_S | 320.01 | 61.57 |
| Q3_K_M | 143.09 | 62.95 |
| Q3_K_L | 270.64 | 62.10 |
| Q3_K_XL | 461.64 | 61.83 |
| Q4_K_S | 191.81 | 72.11 |
| Q4_K_M | 235.89 | 68.96 |
| Q4_K_L | 339.53 | 66.61 |
| Q5_K_S | 553.79 | 65.44 |
| Q5_K_M | 504.44 | 63.99 |
| Q5_K_L | 333.02 | 62.89 |
| Q6_K | 494.74 | 61.86 |
| Q6_K_L | 407.45 | 61.72 |
| IQ2_M | 164.73 | 75.15 |
| IQ3_XXS | 183.95 | 72.42 |
| IQ3_XS | 377.95 | 68.70 |
| IQ3_M | 405.58 | 69.38 |
| IQ4_XS | 244.09 | 63.10 |
| IQ4_NL | 246.45 | 64.37 |
| BF16 | 125.06 | 32.24 |
개 후진 그래프™
PP는 프롬프트가 짧아서 그런지 값이 유의미하게 안정적이진 않은 것 같아서, 그래프에서는 TG만 비교했다.
댓글